Implementing MNIST classifier from scratch in Zig
I recently started playing with Zig - a modern, low-level, general-purpose programming language, sometimes called a modern version of C. I decided to implement a MNIST digits classifier as part of learning the language and refreshing backpropagation. A MNIST classifier is basically a hello world of machine learning/AI. I realized Zig is getting somewhat popular, so I will reflect on my work and provide a few hints for those who would like to undergo a similar learning journey. It's more fun to learn a new language while practicing machine learning basics. And its a way more fun to learn and act as the problems haven't been solved before.
Writing the classifier in Python using popular machine learning libraries would take as little as ~5 lines of code. My hypothesis was that by taking care of everything myself and trying to act as much blind to previous work in the problem space, I would get a much better sense of what pile of work higher-level ML frameworks handle for us. I would also experienced what problems the researchers faced decades back. I simply won't take anything for granted.
Implementing neural net training in a low level language that I am not fluent in was quite challenging and definitely worth it. You can find my implementation on github.com/cernockyd/zig-mnist. However, I am most satisfied with the experience of deliberately not looking to solutions, while at the same time let myself be guided by research papers to stay relatively productive.
Learning Zig
A very nice thing about this project is that its reasonably complex as a starting point to learn both Zig and machine learning fundamentals. I could build on my experience with C without having to worry much about Zig's patterns, standard library, etc. The language itself features only a manageable 20 unique keywords (its more but it doesn't matter). If you are a complete beginner with Zig, I would recommend starting with exercises like Ziglings that teach you all important parts of the language bit by bit. I started with them too. Once you find them too boring, its time to take on a bigger project like this one to get to know the language in a more 'real' setting. A good thing about Zig is that LLMs are not very good at the language yet. There is no free lunch here, just pure understanding.
Project Scope
There is a reason why MNIST is a very popular dataset even though its quite old. There are many research papers and benchmarks available that feature MNIST and still counting. The MNIST classifier requires loading data, representing model of 2 layer neural net, model initialisation end evaluation, error back-propagation to update weights, and a boilerplate for batch-training and collection of metrics. Getting it right end-to-end is notoriously difficult. It probably will require some debugging. To sum things up, all I really had to know was how to work with files, handle memory allocation and use basic math functions. The resulting neural net hits ~96 % accuracy on training data in 20 epochs, similar to most models which use only simple neural net without convolutions etc. You can get to that accuracy with experimenting and helpful resources. Just don't look at them too much, otherwise you would skip the fun part of experimenting.
Good Machine Learning Resources
Its not too simple to implement neural net for a first project. Especially if you are starting with both Zig and ML. However, there is a ton of possibilities to learn and experiment and I think few resources might help you in similar situation.
Personally, I used this project as an opportunity to go through some of the early papers in machine learning and enjoyed chaining through their references. To see what papers they build on and to get the sense of how the early researchers must have felt at the time and how they reasoned through the problems. It is a learning strategy that takes little bit more of time but in my experience it really makes a difference.
It was interesting to read through the foundational papers like Learning representations by back-propagating errors (1986), or reading about the very origins of back-propagation in Cauchy and the gradient method (2012) (spoiler: there is a link to astronomy). It's just completely different experience to go through these and its very hard to pass the experience without being lengthy. I was very sad it was so hard to get to some of the papers as they exist online only in low-quality scans.
Once I was happy with experimenting and got stuck a few times, I found reading through Automatic Differentiation in Machine Learning: a Survey really helpful. This survey introduces back-propagation in a broader scope which promotes a better model of thinking about back-prop than other materials, in my perspective. I also found Practical Recommendations for Gradient-Based Training of Deep Architectures (2012) and Gradient-based learning applied to document recognition (1998) to be very practical for tweaking the neural net and experimenting and getting sense of how other neural net architectures perform on the dataset.
Debugging
The biggest challenge is to get all the moving parts from end to end right. A few times, I encountered bugs that might've been hidden elsewhere in the program (as I wrote only a few tests). Apart from a few numerical problems which I managed to spot after a while, I was accessing memory that I should't. As you can imagine, this resulted in funny predictions.
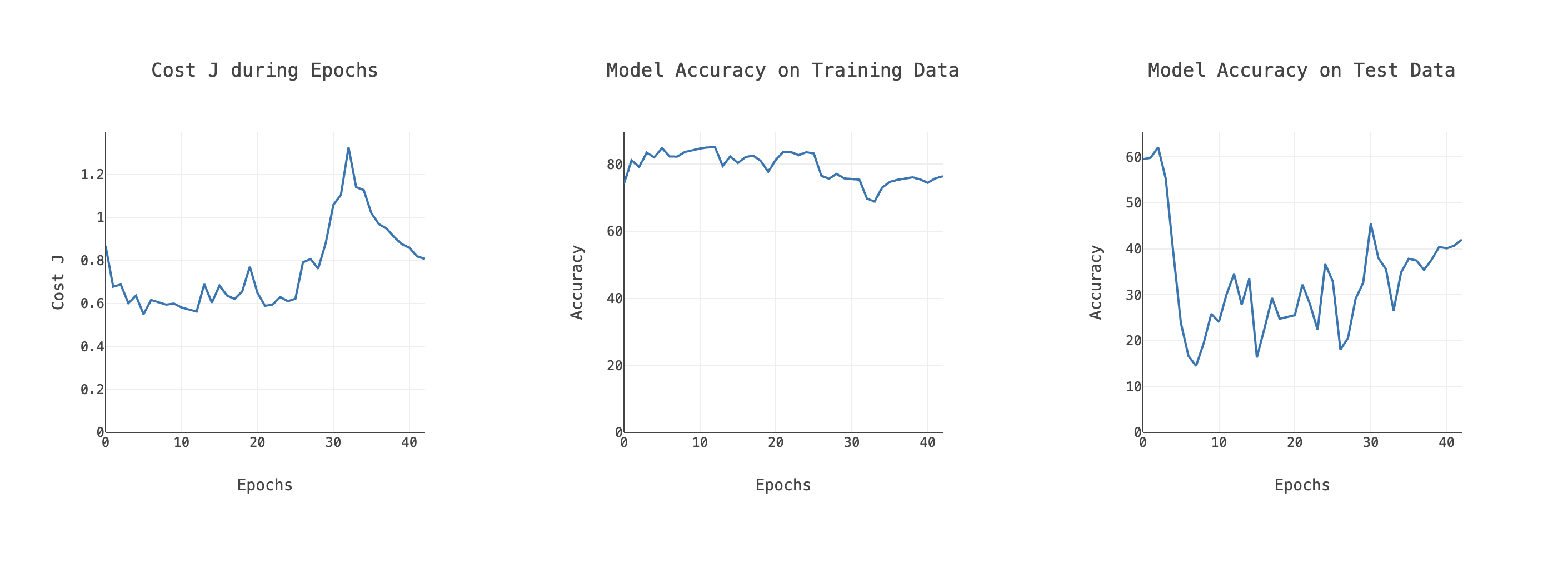 Can you guess what was happening based on these graphs?
Can you guess what was happening based on these graphs?
It was hard to catch until I discovered Zig's runtime safety features. Compiling the program in the ReleaseSafe mode and then running the training led me to the problematic places in code. Very handy indeed. You will see more funny graphs once you start tweaking the model to fit the data. There is one good rule that will save you a lot of time. If your network performs poorly, try fitting a smaller subset of the dataset first.
There is always a space for improvement
The implementation is actually very naive. There are no optimizations. It does not leverage GPU or even SIMD on CPU. I didn't worry about cache hitting either, since it was fast enough for me to finish it and move on. I did not implemented any sophisticated reverse autodiff with a computational graph under the hood. (If you don't understand and feel lost now, don't worry, you can find out later). Hardcoding the equations worked. Logging metrics during training is extremely simple. I mean everything just works. Its a learning exercise after all.
Conclusion
It was a great learning experience for me. Starting with machine learning project like this one might not be the best strategy for everyone as it requires debugging one's knowledge of the problem at hand instead of learning the language, but it was definitely a fun for me as I needed to work on something meaningful. In upcoming updates, I would like to work on some of the shortcomings of the implementation which is indeed quite naive for today's benchmarks. I am also devoting some time to researching what could I possibly abstract into something that would be more like a machine learning framework in Zig. I would like to turn the project into something more versatile while narrowing its scope for specific domain at the same time. To be continued.